How Texti Works?¶
Texti is designed to help you find the best way to clean and preprocess your text documents. It currently supports pdfs only, and works on single files. You can preview how your chosen transformations extract and process the text from your pdf. Once you are happy with the output, you can download the python code behind the sequence in a jupyter-formatted notebook.
First, create a new project, give it a name, and a bit of an explanation of what you intend to do or which corpora would this most likely apply to.
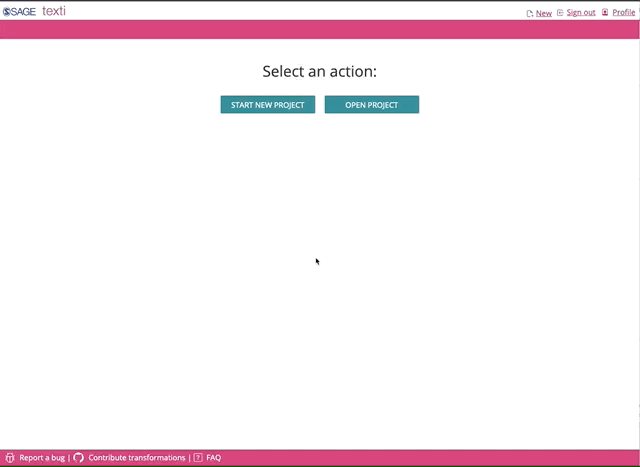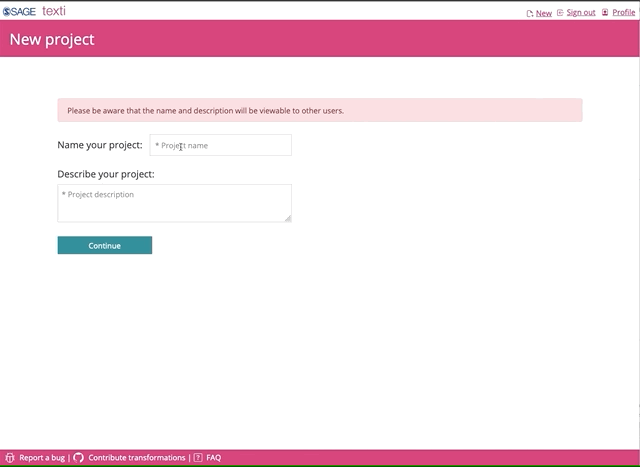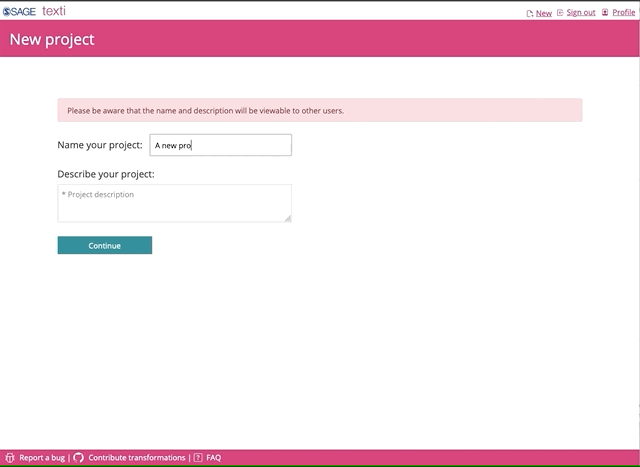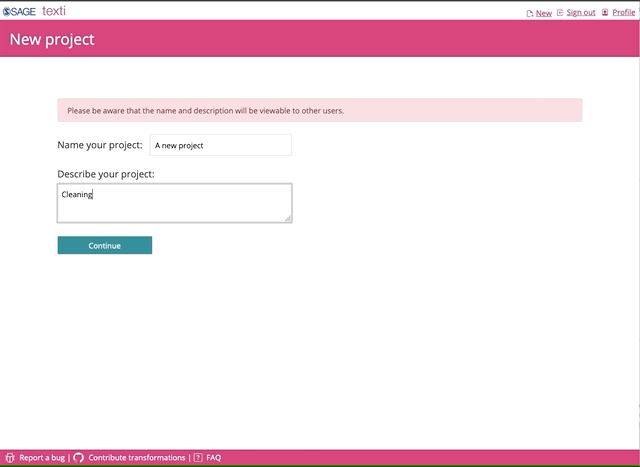
If you are opening an existing project, you can select from all the workflows that have been created with Texti by all the current users. You can open and fork someone else’s project.
Second, you will upload a pdf file, pick any from your working corpus.
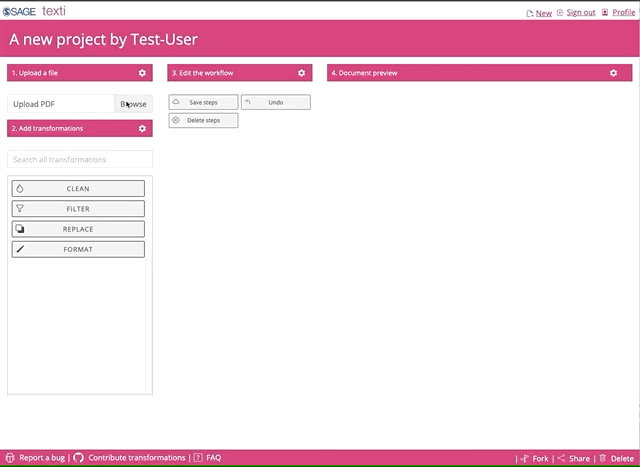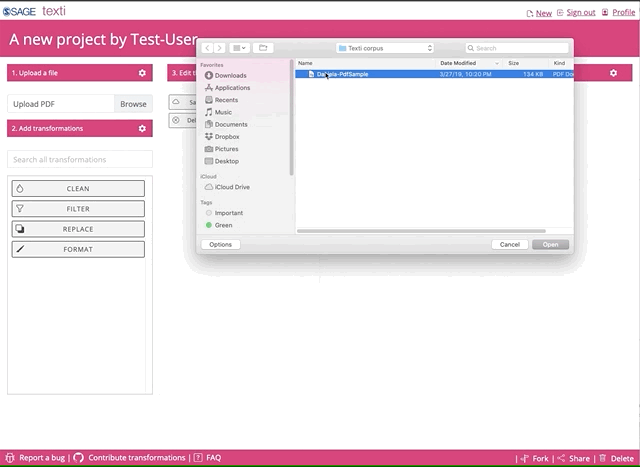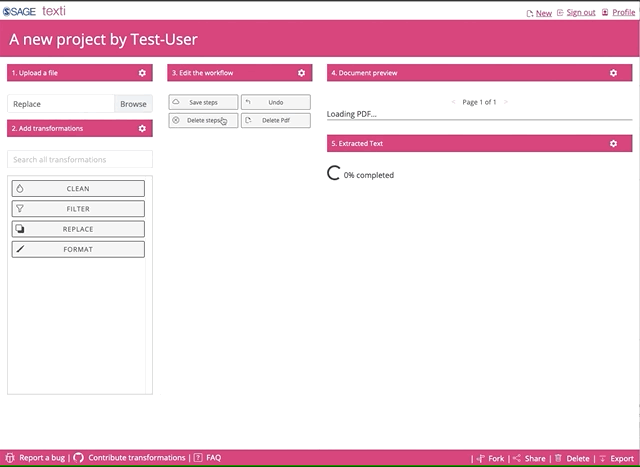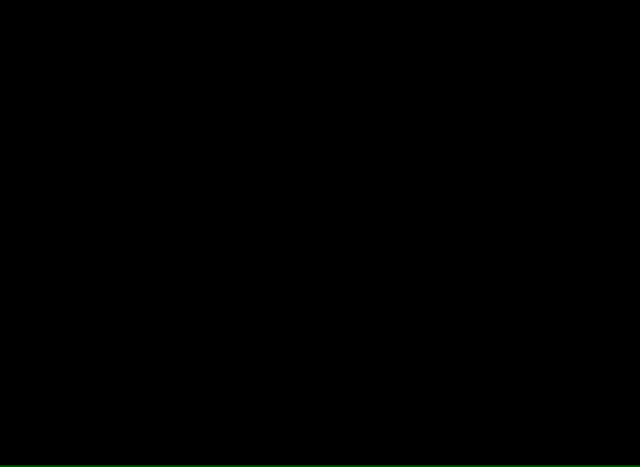
Depending how big your file is, it might take a while to load. Remember, we don’t store your file, all the processing of the file happens in your browser session. You will have to re-upload your file if you logout or your session becomes inactive after 3 hours.
Once you uploaded the file, you can go crazy on the transformations. Feel free to select and try all of them.
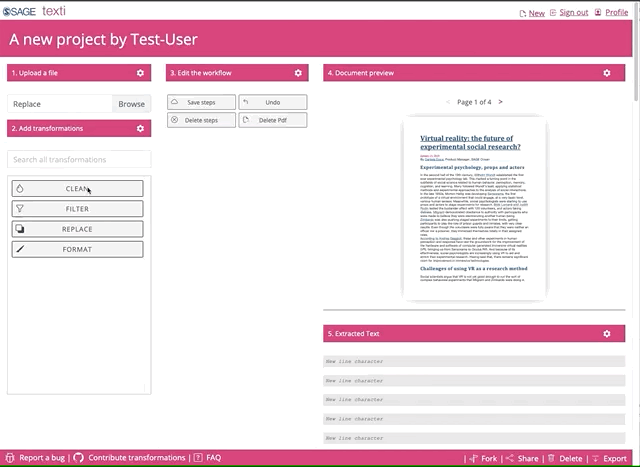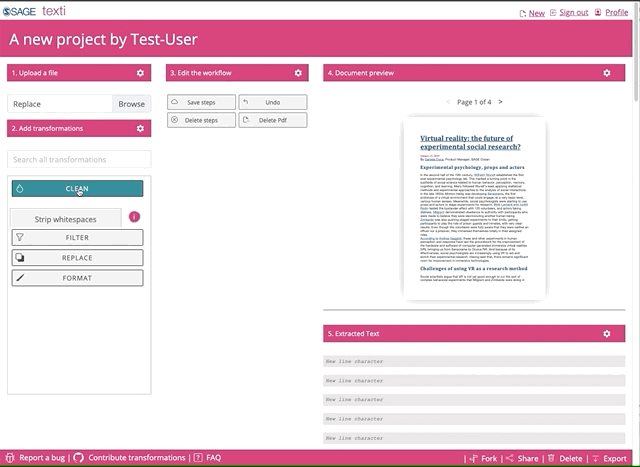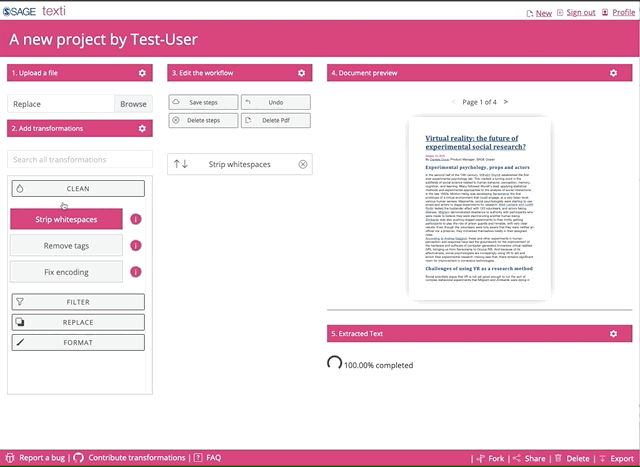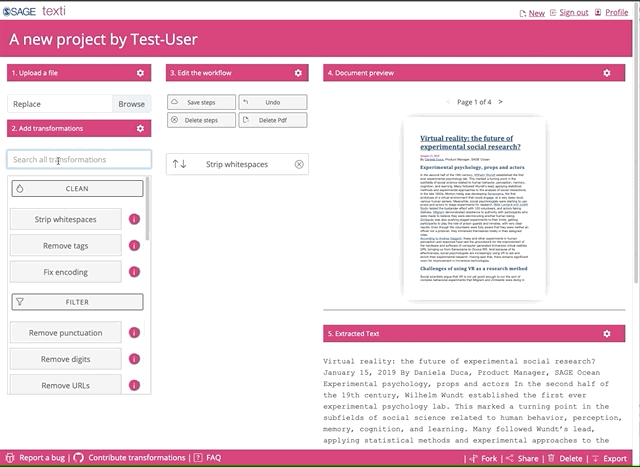
Be patient, the python transformations are applied in the browser, so the more you add, the longer it will take to run. You can also use the search box to find any of the transformations. When you find any missing, let us know, and we’ll work to add them in.
Finally, after you picked and played around with the transformations and are happy with what you see, you can download the python code. You might need to edit it slightly before you can run it on your entire corpus.
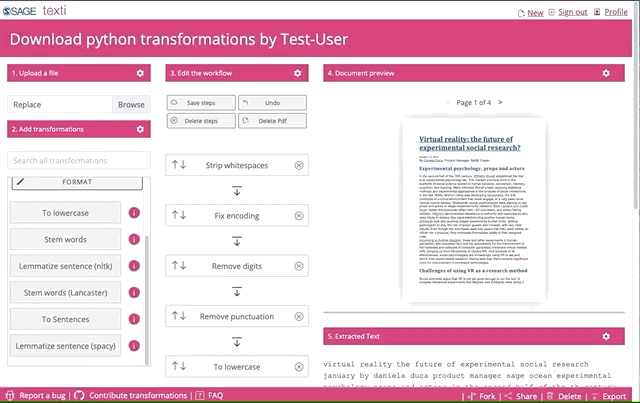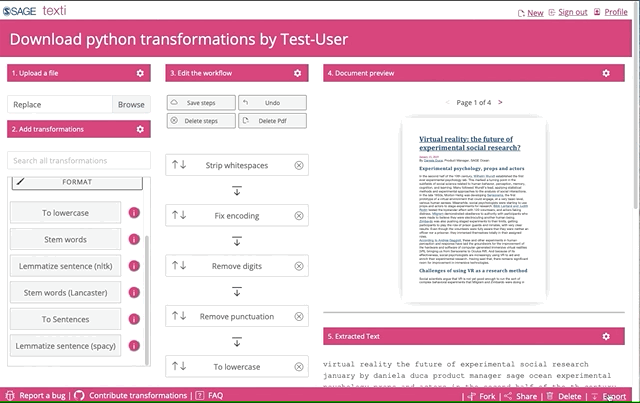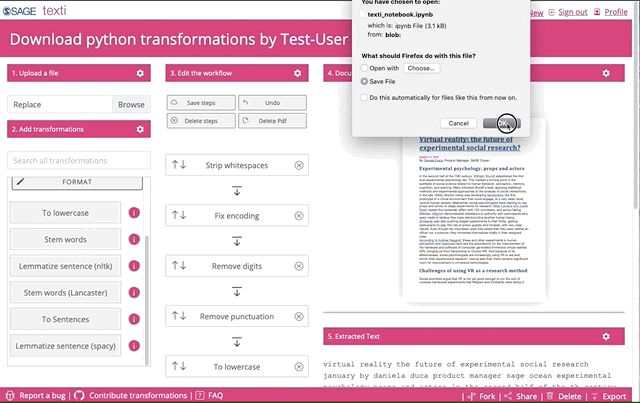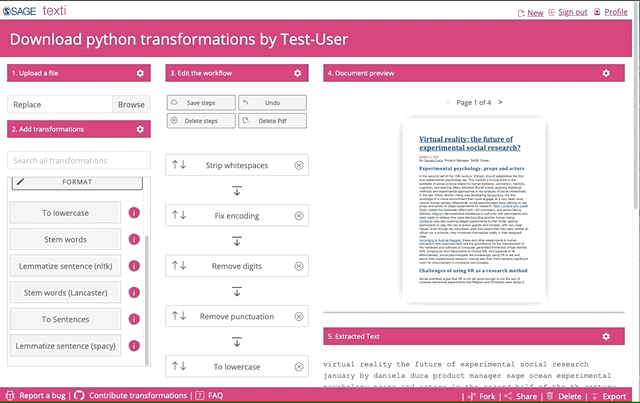
Click on “Export” to download the python formatted file to your local machine. You can then run the code on your entire corpus.
Note
Do you need more help, or have ideas to improve Texti? Contact daniela (dot) duca (at) sagepub.co.uk